
How AI will change software development
I recently had some spare minutes while my wife was driving us to the family Christmas meetup. This time was great for a quick AI coding challenge to see what is possible within a few…
Android development, the Android SDK and mobile phones in general.
I recently had some spare minutes while my wife was driving us to the family Christmas meetup. This time was great for a quick AI coding challenge to see what is possible within a few…

Accessibility in digital design isn't just a matter of ticking a box or following regulations. It is about creating a world where everyone has equal opportunities to engage, interact, and benefit from digital content. When…

As the digital landscape evolves, it’s becoming increasingly essential for businesses to ensure their products and services are accessible to all users, including those with disabilities. Starting from June 28, 2025, companies providing (Android) apps…

Initially, this website was created to present my professional career and ideas around software development. Recently, with my work on paragliding tracklogs and the Thermal Map, it has also become a personal space. This paragliding…
Serverless computing is a cloud-computing execution model in which the cloud provider dynamically manages the allocation of machine resources. At my current project, I had the freedom to create a new service a service from…
Android developers vs. web One great advantage of native apps over web apps is that they don't depend on an online connection to start. Therefore the startup is fast and you can use them in…
As a native apps developer since 2008, I have seen time and time again the wish to develop everything with one toolset. Most often, the toolset of choice is the web, or HTML, CSS and…
Virtual Reality is a hot topic these days. A few weeks ago I had the opportunity to test an Oculus Rift with Touch Controllers. PlayStation VR and HTC Vive have also been released lately. Android Developers like…
Nowadays, every software development team should have a continuous integration server like Jenkins. This is as true for Android developers as for any other platform. It makes sure the current source code compiles and all the…
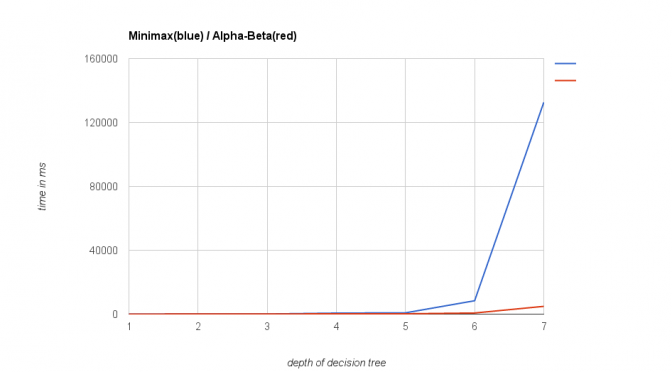
My last post about implementing a turn based game ai became famous on Reddit/Programming for one day. It looks like many developers are interested in this topic. Some readers, with more knowledge of the topic than myself, have…