Serverless computing is a cloud-computing execution model in which the cloud provider dynamically manages the allocation of machine resources.
At my current project, I had the freedom to create a new service a service from scratch and to relatively freely choose the technology stack. The only given was that it should either run inside the old datacenter or on AWS.
Serverless
Having experience with administrating root servers in the past, I also know how easy it is to fail at that task. It takes a lot of effort to keep a system up to date, adjust the configuration for changing requirements and handle hardware failures. With serverless services, like AWS Lambda, all this is abstracted away and handled by the Cloud provider. It auto-scales your service on demand when the load increases. Even better, AWS Lambda will only charge you for the number of requests. If you don’t use a service the only thing you pay for is the zip file stored on S3.
Compared to a typical service based on virtual machines or containers, these benefits are huge. However, they also come with a downside. Most notably is the performance impact. AWS will kill idle Lambda instances and spin them up on demand. This means the service has to be loaded from S3, extracted and started when the first request in a longer period of time comes in. There are huge differences in the startup time of certain technologies. Node.js and Python are among the fast end, while Java with Spring takes a lot longer to start.
Caching
As instances can be stopped at any time, this also affects caching strategies. There is a simple cache in API Gateway which caches full responses. It can be activated by checking a checkmark and setting the maximum size. However, many times you don’t want to cache the complete response, but pieces of information required to compute it based on the input values.
It is possible to cache data inside a Lambda, but there is no guarantee about how long it will be available. This depends on the load, access patterns and probably how many resources Amazon currently needs. If you want more control you have to use an additional service like Elasticache. However, this part cannot be started on demand. As a central instance which has to be available and quickly serves requests, the cache has to be up and running all the time and you will be charged even when it is not used.
In the case of my service, the load is high enough to make sure there is one Lambda instance running all of the time. It is not always the same instance, but changes are rare enough to provide a good amount of cache hits.
Wrap up
Going serverless was a great choice and is superior to manually running a service in a container, VM or even the bare metal in many ways. It provides the option of scaling to nearly an infinite amount of requests (whatever Amazon can handle) without the hassle of configuring complex auto-scaling strategies.
Related Posts

German Paragliding XC Champion
Initially, this website was created to present my professional career and ideas around software development. Recently, with my work on paragliding tracklogs and the Thermal Map, it has also become a personal space. This paragliding…
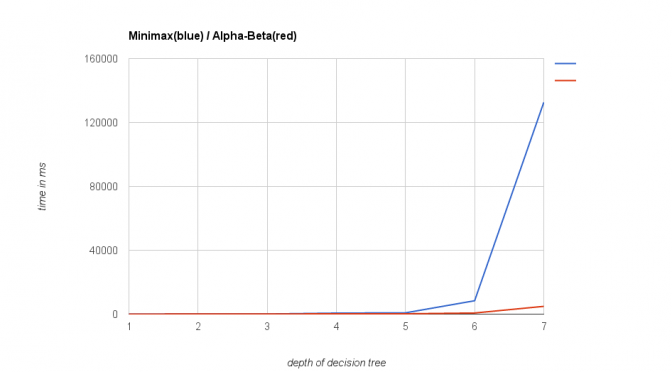
Implement a turn based game AI with optimizations
My last post about implementing a turn based game ai became famous on Reddit/Programming for one day. It looks like many developers are interested in this topic. Some readers, with more knowledge of the topic than myself, have…
Native- and Mobile Web Apps
As a native apps developer since 2008, I have seen time and time again the wish to develop everything with one toolset. Most often, the toolset of choice is the web, or HTML, CSS and…