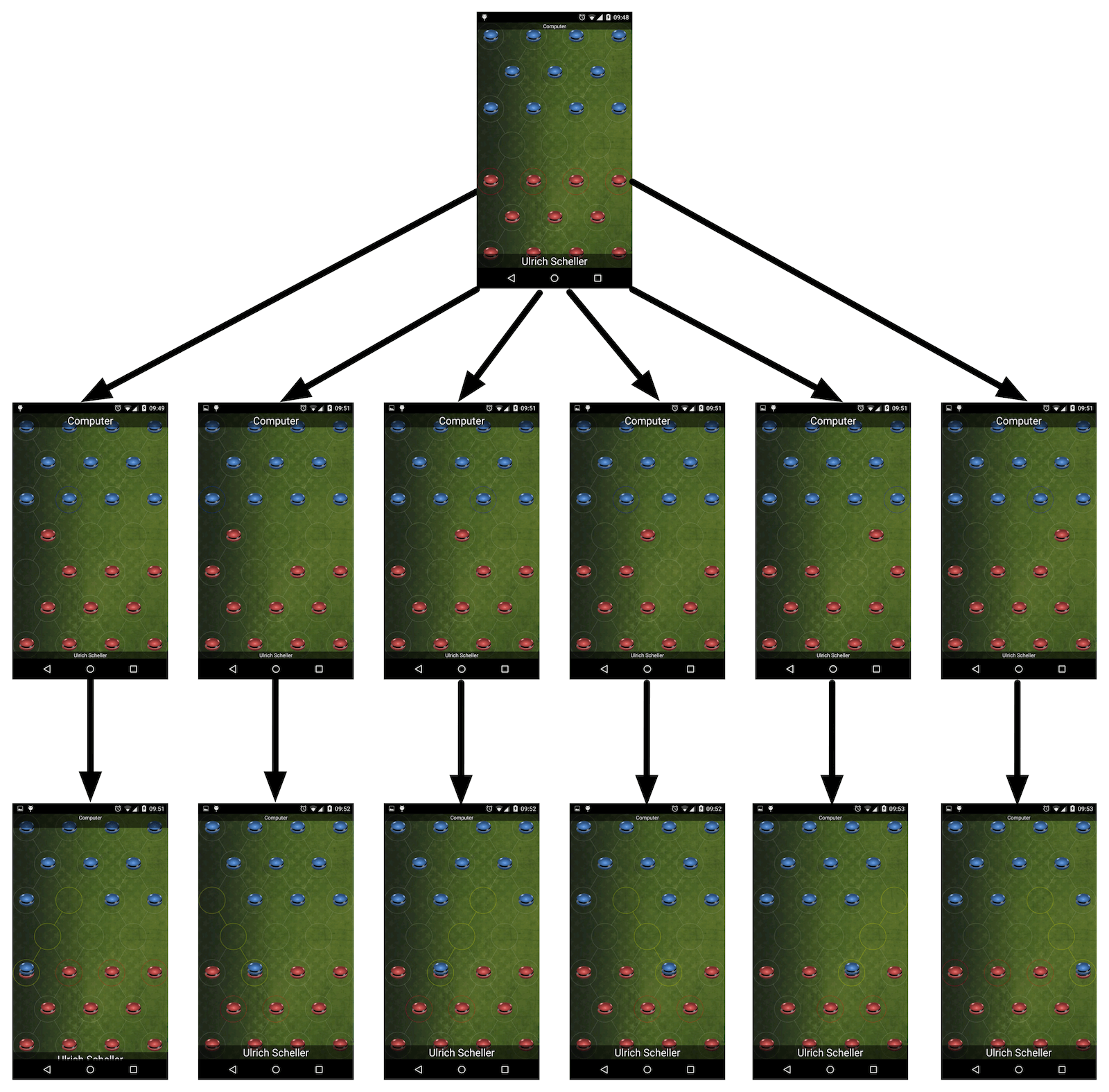
Implement a turn based game AI (on Android)
Sunday June 21st, 2015
Game AI Developing a game AI can be as much fun as playing, especially when creating your own computer opponent. I am going to present you a simple pattern that works for nearly all turn based game