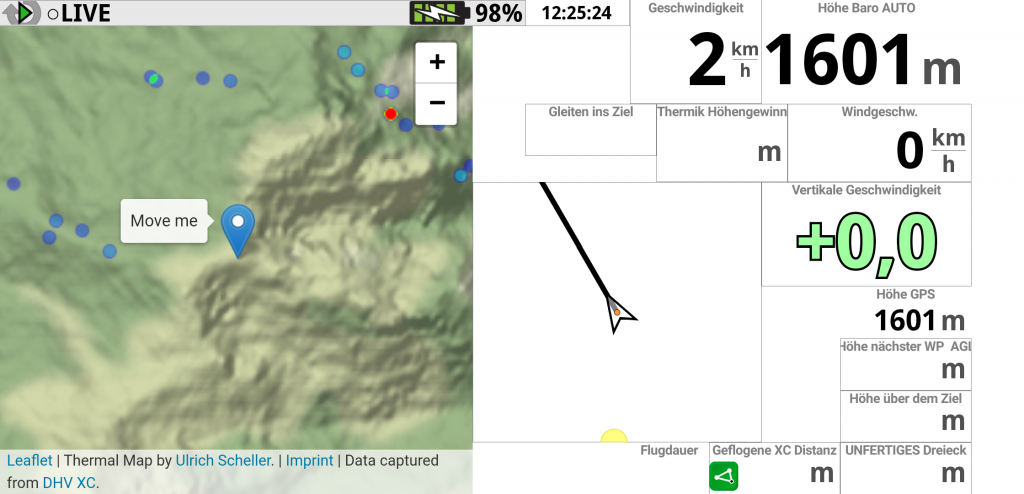
See the Thermal Map while flying
Thursday July 8th, 2021
Many pilots asked me if it is possible to use the Thermal Map while flying. And indeed, this was the initial idea of the whole project. But it is hard to debug when you need