Implement a turn based game AI (on Android)
Game AI
Developing a game AI can be as much fun as playing, especially when creating your own computer opponent. I am going to present you a simple pattern that works for nearly all turn based game ai’s, especially where there is a defined set of possible moves. This pattern is powering my own Laska for over 6 years already and I have been using it before for personal 4-Wins and Tic-Tac-Toe games.
For this you don’t need a perfect solution, but something that can win against most human players. It should prevent making obvious mistakes and the strength must be easily adjustable. I will show an algorithm that works for two players, but can easily be extended to more.
Basics
In a turn based match we always have moves made by every player. When saying move, what I actually mean is a Ply, or half-move. That is, the move of only one player. Our game AI will look a defined number of half-moves into the future and find the best possible move.
Your game should have a state which can be classified as good or bad. So in chess, we have a winning situation when the King will be taken out in the next move. This is great for one player, and really bad for the other one. There is also a lot in between. Let’s say one player has more Pawns than the other. This would be a good indicator that he is in a stronger position. In Laska, a winning situation is when the other player has no more possible moves available.
Algorithm
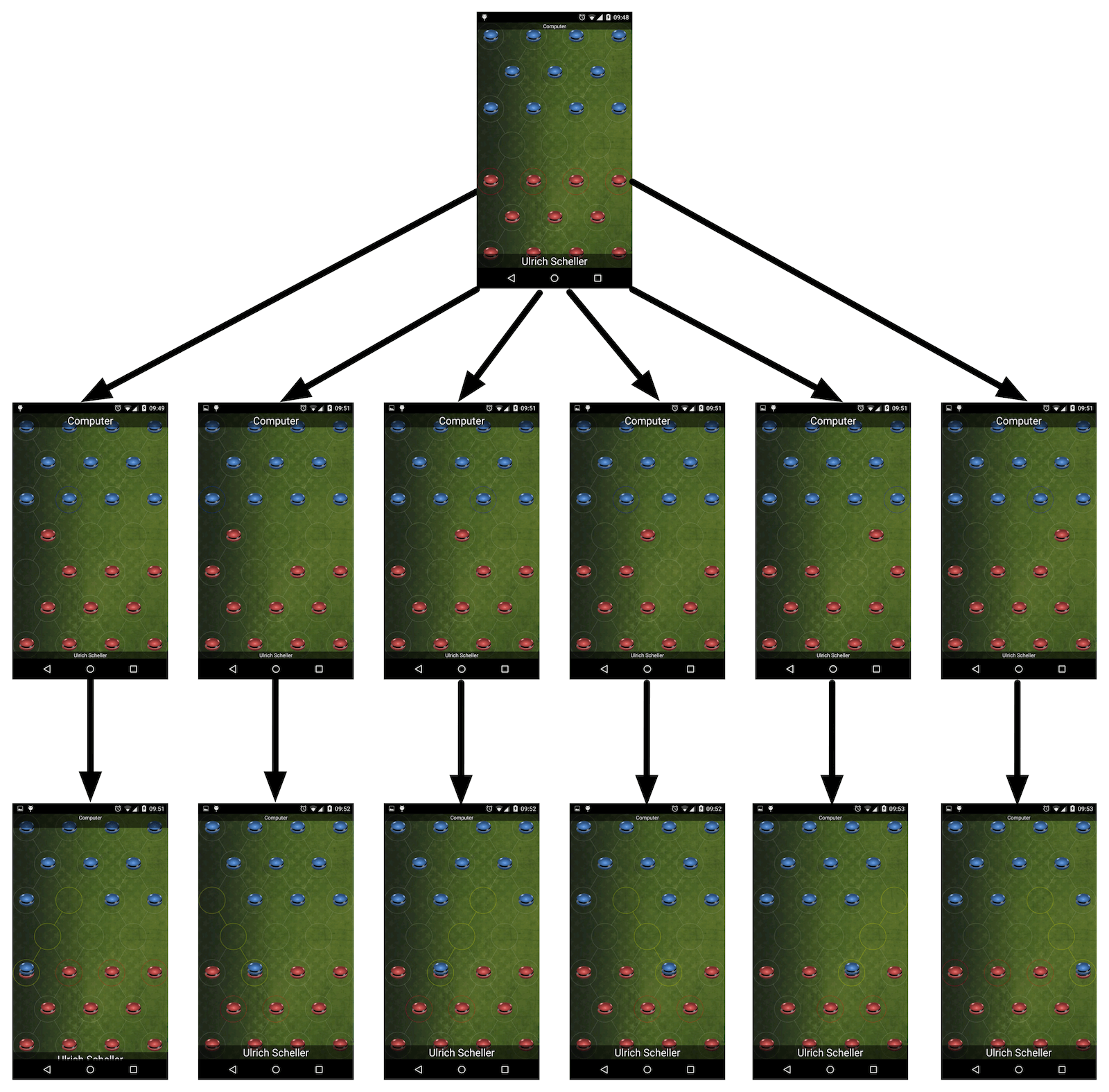
There is a simple pattern that works for all these round based games. It is based on a decision tree of all possible moves and the classification value of the game situation.
From the starting position in Laska, there are four movers with six possible moves. Every move will lead to a forced jump. After that, there are either two possible jumps or three possible moves, depending on which Pawn was moved at the beginning.

If you can attach a value of the game situation to each node in the graph, it will be easy to select the best move. You need to figure out the subtree with the best worst-case situation.
For this, all your game has to provide is two methods:
- getPossibleMovesOfActivePlayer(field), which will return all the possible moves for the active player on a given field.
- getValue(field), which will return a useful value of the situation. It should be high positive when player 1 has won and high negative when player 2 has won.
With these methods available, you can find out what is the best move:
public Move bestMove(int recursionDepth) {
int maxValue = Integer.MIN_VALUE;
Move bestMove = null;
Vector<Move> possibleMoves = field.getPossibleMovesOfActivePlayer();
if (possibleMoves.size() == 1) {
// if there is only one possible move - no need to calculate the value
return possibleMoves.firstElement();
}
for (Move move : possibleMoves) {
int value = getValueOfMove(move, recursionDepth);
if (value > maxValue || (value == maxValue && new Random().nextInt(2) == 1)) {
maxValue = value;
bestMove = move;
}
}
return bestMove;
}
The method starts with an initial value of Integer.MIN_VALUE. Then it considers all possible moves. If there is only one move available, this is automatically the best option. This is an optimization which gives tremendous speedups when using a high recursionDepth. The recursionDepth indicates the size of our graph. The more we look into the future, the stronger our ai gets.
In all other cases, where we have more than one possible moves, we calculate the value of all of them with the specified recursionDepth. The part with Random().nextInt(2) is included to make the ai less predictable. If you leave out this randomness, the computer will always play the exact same game, if you do so as well.
So what does getValueOfMove() do?
protected synchronized int getValueOfMove(Move move, int recursionDepth) {
int player = field.getPawn(move.from).pawnOwner();
LaskaField nextField = new LaskaField(field.getFieldClone(), field.activePlayer);
nextField.movePawn(move);
LaskaAI nextAI = new LaskaAI(nextField);
int value;
if (recursionDepth > 1) {
Move bestMove = nextAI.bestMove(recursionDepth - 1);
if (bestMove == null) return 1000; // when game is won
value = -nextAI.getValueOfMove(bestMove, recursionDepth - 1);
} else {
value = nextAI.getValue(nextField.field, player);
value -= nextAI.getValue(nextField.field, 1 + (player % 2));
}
return value;
}
First it creates a clone of the field object for further calculation. On the cloned field (nextField), the given move is applied and the active player changed to the next one. With this new field, we now calculate the value of the following field. The simple case is when recursionDepth is exactly 1. Then we add the field value for the active player and subtract the field value for the other player. In my case, the getValue() method only factors in the Pawns of one player. Therefore it has to be called twice.
The more complex case is when recursionDepth is greater than 1. Then we recursively call the method bestMove() from above with a recursionDepth reduced by one. If there is no possible move and the bestMove is null, then the active player has won the match. So we return 1000, a very high number that can only be reached in a winning situation.
If there is a bestMove, this is what the opponent will choose to do. So for our move, this bestMove is the worst case that can happen to us. Because the value of the bestMove us calculated from the other players point of view, we have to negate it with value = -nextAI.getValueOfMove(bestMove, recursionDepth – 1);
Calculating the value
As mentioned above, you need to provide the getValue() method specific to your game. It receives the game state as input and returns an integer describing how “good” it is for the current player. In the case of Laska it returns values in the range of -1000 to 1000. Most likely there will be no perfect or correct return value. You have to create your own method and fine tune it over time. The better your getValue() method gets, the stronger your AI will be and you don’t need to use a high recursionDepth.
The weakest getValue() method will only return a negative number for a lost match and a positive number for a won match, otherwise zero. In this case you would have to use a recursionDepth that calculates all possible moves until the end of the game. In some cases this might be an option. The perfect getValue() method will already know all possible outcomes and give you perfect values. Your algorithm therefore only has to use a recursionDepth of 1.
Since most of the time it is neither possible to calculate all possible moves until the end nor to create a perfect getValue() method, we have something in between. In Laska the values are calculated like this:
- For all of my pawns add 10
- Add 5 for every of my pawn slices below the top, until there is an opponents pawn slice
- If pawn is an officer add another 20
- Add 2 if a pawn is on an outer field, instead of in the middle

For other games, think of indicators that obviously help towards winning. If pawns are taken out of the game compare the number of pawns. If you need 4 in a row to win give some value to 3 in a row, at least if there is still space for a 4th.
Unit Testing
AI is a poster child for using Unit Tests. In fact, you will have a hard time if you leave them out. Especially annoying are minor mistakes, that don’t break your algorithm but weaken the ai significantly. I have started without proper testing and ran into that problem far too often. Some years ago I realized the value of testing and can iterate much faster now.
You can easily test all the methods with synthetic input. Does field1 give a higher value than field2? Make sure the best move in field1 for player 1 is X. Whenever you think My AI should make this move now but it is not, create a test case and fix it. Either you will find the mistake, or realize that the AI in fact was correct and you were wrong. This way you will soon have a stable and strong AI.
Another cool and fun usage is to let one version of the game AI play against an improved one. During optimizing the getValue() method, I could only believe a change would make the computer stronger. This was until I created a test that played 100 matches of the new version against the old one. Now there is an evaluation of the strength and I can be sure whether my change is an improvement or just a change.
Optimizations
The algorithm above is not meant for winning a competition or to be perfectly efficient. If you want this, you can start with Peter Norvigs Artificial Intelligence: A Modern approach and read through some current papers. However, the algorithm is a pattern that works for nearly all turn based games and gives decent results, so you can move on creating all the other important aspects.
Some things that can be improved:
- In every getValueOfMove() the whole field object is cloned. While this wastes some computation time, I found that the algorithm is still fast enough even on mobile phones. The field objects are not too big and cloning them simplifies the following steps. Also this makes it more easy to parallelize computation if that would be necessary.
- After bestMove has been calculated, the value is calculated by stepping into the same recursion again: value = -nextAI.getValueOfMove(bestMove, recursionDepth – 1);
- You can tune the randomness in bestMove() by collecting all moves of the same value and make an equally weighted choice between them.
If you can think of more, please tell me in the comments.
Wrap Up
As you can see, implementing a computer opponent in a turn based game is no rocket science. You only need to supply two methods and find the optimal move from the resulting tree as described here.
If you want to see the described algorithm in action, download Laska from the Play Store.
I actually implemented something like this for my mid-term project in a CS unit earlier this semester, but it was for a real time game.
Another known optimisation worth mentioning is called alpha-beta pruning. On each level of the game tree, record the highest seen and lowest seen value for each of the children of the level below. As you move across siblings, if the current node you’re evaluating is seeking to maximise the game score and the highest value you’ve seen so far out of the children on other branches at that level is lower than the value you just saw, you can save the value and stop processing that branch there, since the level above you is going to pick the lower value from the previous branch. Its efficacy depends on how well sorted your nodes are when the game tree expands, which usually depends on a cheap-to-evaluate heuristic.
And as you mentioned, unit testing here is key. Its insanely easy to screw up the AI when implementing something like a-b pruning – its really important to make sure that both versions work in exactly the same saw.